Gibberish by Raku
[2] Published 24. March 2019. Rakuified 7. March 2020Perl 6 → Raku
This article has been moved from «perl6.eu» and updated to reflect the language rename in 2019.
Gibberish is defined as «Spoken or written words that have no meaning».
In this article I'll present a Gibberish Generator, but before doing so I'll discuss some programming features that makes it relatively easy to make such a generator in Raku.
BagHash
TheBagHash data type is similar to a hash, but the values
can only be positive integers. We can use an array to give us a BagHash like this:
File: baghash
my @a = <a b c d e f g h i j a a a a d d d d d d d j>;
my $a = @a.BagHash;
say $a; # -> BagHash(a(5), b, c, d(8), e, f, g, h, i, j(2))
The value is the number of times the key was present in the array. The value «1» is implicit, and is not shown in the output above.
If you assign a BagHash to a hash variable
(a variable with the % sigil), it will be coerced to a hash.
Note that looking up a nonexisting key gives «0», and not an undefined value (as with a hash):
File: baghash2 (partial)
say $a<a>; # -> 5
say $a<b>; # -> 1
say $a<x>; # -> 0
See docs.raku.org/type/BagHash for more
information about BagHash.
Random Selection from a BagHash
When we usepick to give us a random value from
a list (or array), we get one of the values at random (with equal probability for each of
the elements). But when be do the same on a BagHash the weight (or
frequency) is taken into account.
An example:
File: baghash-pick-weighted
my %hash = ( This => BagHash(:is => 9, :was => 1)); # [1]
my %result;
%result{ %hash{"This"}.pick }++ for ^ 1_000_000; # [2]
say "$_: %result{$_}" for %result.keys.sort; # [3]
[1] We set up a normal hash, with the word «This» as the only key. The value is a
BagHash of words (the keys; «is» and «was») with weight (the values «9» and «1»).
[2] We apply pick on the BagHash to get a word (either «is» or «was»),
and increase the counter for the chosen word by one.
[3] And finally we print the numbers.
$ raku baghash-pick-weighted
is True: 899944
was True: 100056
The distribution is almost spot on; at about 90% for «is» and 10% for «was».
Up to now I could have used the Bag
type instead of BagHash, but that will not work in the code in the rest of
the article. See docs.raku.org/type/Bag
for more information about Bag, if you want to know more.
Gibberish, Next Word
The Gibberish Generator starts with a real text, and builds up the structure where we have a hash of all the words, with aBagHash of the words following it
together with the weight (or frequency). Then it selects the gibberish words according
to the weight, and the BagHash and pick combination gives us
almost everything we need for free.
First a module doing the counting:
File: lib/NextWord.pm6
unit module NextWord;
our sub word-frequency(@words) # [1]
{
my %frequency; # [2]
my $previous = ""; # [3]
for @words -> $word # [4]
{
%frequency{$previous} = BagHash unless defined %frequency{$previous}; # [5]
%frequency{$previous}{$word}++; # [6]
$previous = $word; # [7]
}
return %frequency; # [8]
}
[1] The module has one procedure, and it takes a list of words as argument. (This is done so that
we can control how a line is split into words. We'll get back to why that is useful later.)
[2] The return value from the procedure; a hash of words, where the value is a BagHash
of words following it (with the weight).
[3] The start problem is tackled by hard coding it as "" (an empty string).
[4] Then we iterate through the list of words.
[5] If we haven't encountered the left side word before, we initialise the BagHash.
If we skip this, we'll get an automatically created hash when we access it in the next line.
And that would be bad.
[6] Then we add to the weight of the word combination.
[7] And remember the word, so that we have a left side the next iteration.
[8] Returning the word frequence data structure.
And a simple test program to show that it works:
File: wordfrequency-test
use lib "lib";
use NextWord;
my $sentence = "This is the end of the beginning, or the beginning of the end.";
my %dict = NextWord::word-frequency($sentence.words); # [1]
say "'{ $_ }' -> { %dict{$_}.perl}" for %dict.keys.sort; # [2]
[1] Using words works pretty well, but note that it splits the string on space
characters only, so punctuation characters are not removed from the word they are attached to.
[2] Printing the words in the hash, and the BagHash structure.
Running it:
$ raku wordfrequency-test
'' -> ("This"=>1).BagHash
'This' -> ("is"=>1).BagHash
'beginning' -> ("of"=>1).BagHash
'beginning,' -> ("or"=>1).BagHash
'end' -> ("of"=>1).BagHash
'is' -> ("the"=>1).BagHash
'of' -> ("the"=>2).BagHash
'or' -> ("the"=>1).BagHash
'the' -> ("beginning"=>1,"end."=>1,"end"=>1,"beginning,"=>1).BagHash
my @words = $sentence.words;
@words.push("");
my %dict = NextWord::word-frequency(@words);
The output is the same as for «wordfrequency-test», with the addition of this line:
'end.' -> (""=>1).BagHash
We can summarise the data structure we get by «NextWord::word-frequency» in this figure:
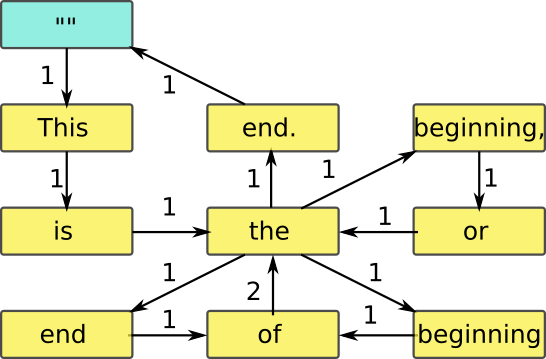
Note the start and end in the upper left corner (marked with ""), and that all the weights
are 1, except for of -> the which is 2.
Gibberish, First Try
Equipped with the «NextWord» module, and our knowledge of pick we can make a Gibberish Generator. We feed the program with a real text, and it gives us back gibberish based on a weighted random selection of neighbouring words in that text. File: gibberish
use lib "lib";
use NextWord;
unit sub MAIN ($file where $file.IO.r, Int $limit is copy = 1000); # [1][2]
my %dict = NextWord::word-frequency((slurp $file).words); # [3]
my $current = ""; # [4]
loop
{
$current = %dict{$current}.pick; # [5]
print "$current "; # [5]
print "\n\n" if $current ~~ /\.$/ && (^5).pick == 0; # [6]
last if $limit-- <= 0 && $current ~~ /\.$/; # [7]
}
print "\n";
[1] We specify a file to use as source. The where clause is there to ensure
that it is a (readable) file.
[2] The optional $limit value is used to specify the numbers of words to produce.
It defaults to «1000».
[3] We use slurp $file to read the file in one go, apply words on
it to get a list of words, and passes that list to the module.
[4] This is important, so that we can get the first word (which is the same as the first word
in the original file - as that is the only one with an empty left side).
[5] Then we pick one word at the time, printing it.
[6] We have to insert sections ourself, as words doesn’t recognize newlines
(it actually ignores all sorts of whitespace), so the result would have been one very long line.
I have chosen to add a newline after a word ending with a period - with a 20% probability.
[7] Counting down the number of words. If we have reached the limit, we go on until we get a
word ending with a period (to get a graceful stop, and hopefully something that looks like a
complete sentence) before actually stopping.
Note that we don’t have an end pointer so if the program goes there - and we have no other word used after that one somewhere else in the text, it will fail when it tries to access the next word.
Consider this line (from «wordfrequency-test»):
"This is the end of the beginning, or the beginning of the end.".words;
And what happens if it chooses «This» → «is» → «the» → «end.» And then tries to go on?
The failure isn't critical, as we get an undefined value - and a warning. An undefined value stringifies to an empty string, and that works fine when we look for the next word. (Which in this case is «This».)
Gibberish, Second Try
The end pointer problem is annoying, but not really serious (as we could redirect the output to a file, and the warnings doesn't end up there as they are written to STDERR), but we have other issues with this program as well:- The start word is the same as in the original text
- Sections are added by the program code, and not based on the pattern (or frequency) in the original text
This modified version fixes all those problems:
File: gibberish2
use lib "lib";
use NextWord;
unit sub MAIN ($file where $file.IO.r, Int $limit is copy = 1000); # [1]
my @words;
for $file.IO.lines -> $line # [2]
{
unless $line { @words.push(""); next; } # [3]
@words.append($line.words); # [4]
}
@words.append(""); # [5]
my %dict = NextWord::word-frequency(@words); # [6]
my $current = ""; # [7]
loop
{
$current = %dict{$current}.pick; # [8]
print "$current "; # [8]
print "\n\n" if $current eq ""; # [9]
last if $limit-- <= 0 && $current eq ""; # [10]
}
[1] As above.
[2] We read the file line by line this time,
[3] and passes an empty string if we read an empty line (to indicate a new section).
[4] Adding the words (with append instead of push so that we
have one list).
[5] Adding the end pointer that I (on purpose) forgot on the first try, as it
didn't fit in with the very compact code reading the file, getting the words and passing
them on to the module - in one line of code.
[6] And off we go, letting the module do the job.
[7] This one will now match at either the very first word - or after an empty line
(a paragraph). So the very first word in the output will be the first word in
any of the sections in the input file.
[8] Pick one word at a time, printing it.
[9] Add a paragraph if we encounter one with pick. (The first newline
end the current line, and the next one adds an empty line after it.)
[10] And we do this until we have reached the word limit, and found the end of a
paragraph.
More about the start and end pointers
Consider a source text with four paragraphs. Only the first and last words in each one are shown, and the rest has been replaced by «...» as they don't matter here:
I ... actually.
This ... be.
This ... paragraph.
Support ... value.
We can summarise the data structure we get by «NextWord::word-frequency» in this figure:
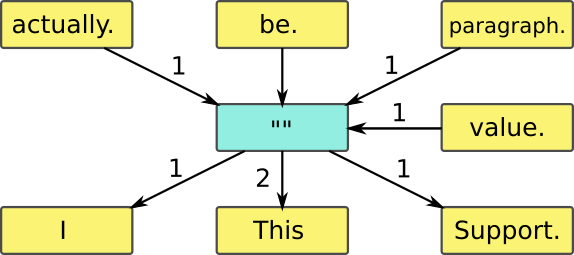
We start by picking the first word with "" as index (marked with [7] in «gibberish2»), and this gives us one of «I», «This» and «Support». When we encounter the end of a paragraph (an empty text; marked with [3] in «gibberish2») we print a paragraph (marked with [9] in «gibberish2»), and goes on to select the next word - which is the first word of the new paragraph. And again, we start with "" as index, so it does the same as for the very first word.
The end pointer (from «value.» to «») ensures that the very last word in the source text has a successor.
Use Case
I don't recommend using this to produce text in a professional setting (unless the aim is to annoy the readers), but if you do, use it on plain text without headings and other "noise" that messes up the randomness (as e.g. a play manuscript with role names and stage directions). Quotes and parens will stand out if they are unmatched, as they are almost certain to be.To avoid litigation issues I have used it on one of my own texts, the short story Hello. Running the Unix «wc» (word count) program on it (the plain text version, not the html file) gives a word count of 485. I give this value back to the Gibberish Generator, to avoid too many repetitions:
$ raku gibberish2 Hello.txt 485
I did this five times, and the result is available here (without any editing, except added html markup):
They are partly amusing, mostly incomprehensible, and utterly devoid of any meaningful meaning (so to speak). At least compared to the original text.
Possible Extensions
- Add support for newlines, so that it can be used on program code. Probably in combination with a pretty printer on the output (to regain indentation)
- Add support for more than one word ahead (try with two), so that the output feels more natural. This will require longer input texts to avoid too many repetitions
- Support for more than one input text file at a time, primarily to give more combinations to choose from. (Certain phrases are repeated too many times in the 5 gibberish texts I have generated, and this can reduce the risk.) Change the limit to a named argument to make this easier
- Extend «word-frequency» to return the number of words, and use that as limit instead of the default 1000. A user specified limit will override this value